Research outcomes of the Program for the Promotion of Next Generation Research Projects
Faculty of Science and Technology
Shingo Murata
With the development of machine learning techniques such as Bayesian inference and deep learning, it is expected that we will realize a future society in which intelligent robots play an active role in our daily lives. Among intelligent robots, collaborative robots in particular, are required to generate adaptive behavior by autonomously inferring a task goal state from an environmental situation while performing dynamic optimization of the inferred goal state based on a human partner's behavior. This research project aims to develop a computational framework for collaborative robots that can acquire this ability through their own sensory-motor experience by reference to the principle of brain information processing.
We especially focused on the so-called predictive processing based on the free-energy principle proposed by Prof. Karl Friston, a theoretical neuroscientist at University College London. In predictive processing, human cognitive functions such as learning, perception, and action are considered as different processes to minimize variational free energy. Variational free energy is an information-theoretic functional and consists of the accuracy term (prediction errors) and the complexity term (Kullback-Leibler divergence between approximate posterior and prior distributions). For example, perception and action can be understood as a process to minimize the variational free energy by changing the internal states of the brain and by changing the external states of the world (or sensory states), respectively. In this study, we developed a computational framework based on this idea of the predictive processing by using deep neural networks and implement this framework into a collaborative robot. By conducting experiments involving a human―robot collaborative task, we were able to evaluate the ability of a collaborative robot equipped with the developed computational framework.
Our computational framework mainly consists of three deep neural networks: (1) a goal-inference network, (2) a goal-recognition network, and (3) an action-generation network (Fig. 1). The goal-inference network and the goal-recognition network are the extension of a conditional variational autoencoder (CVAE). These two networks enable the framework to infer a latent goal state from only the initial image of a task space. The action-generation network based on a long short-term memory (LSTM), which is a type of recurrent neural networks (RNNs) with a gating mechanism, generates a prediction about the visuomotor state from its current state and the inferred latent goal state. In the learning phase, the goal-inference network and the goal-recognition network are first trained to minimize the variational free energy by using a gradient method. The action-generation network is then trained to minimize visuomotor prediction errors by using the gradient descent method. These trained neural networks are finally integrated as a framework, and this framework is implemented into the robot. During the action generation phase, a robot equipped with the framework first infers a latent goal state using only the initial image of a task space. The inferred latent goal state is optimized to minimize visual prediction errors to adapt to changes in the human partner's goal state. We expected that the robot would be able to generate adaptive behavior based on this dynamic inference process of the human goal state.
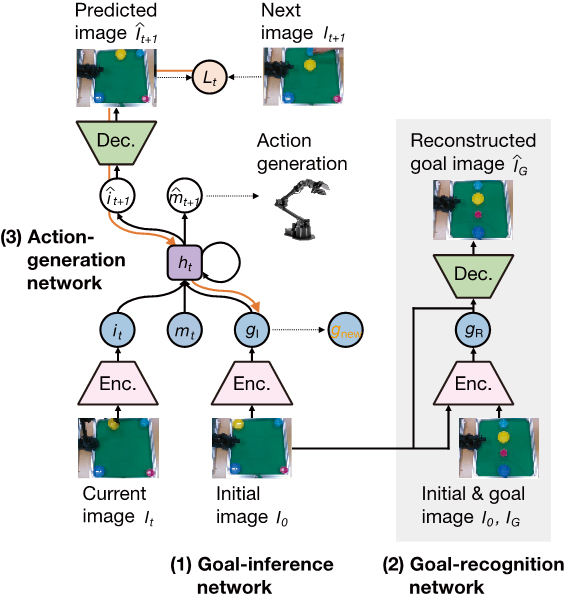
Fig. 1.
Overview of a computational framework consisting of (1) a goal-inference network, (2) a goal-recognition network, and (3) an action-generation network.
To evaluate the framework, we conducted experiments involving a collaborative object arrangement task between a human and a robot equipped with the framework. In this task, a human and a robot were required to place multiple objects that can be manipulated from their respective positions toward a specific goal state in a workspace. The goal state was shared between the human and the robot before starting the task or it was inferred from only the initial image of a task space. The human was allowed to change their goal state in the middle of the task execution. We tested whether the robot can dynamically infer the changed human goal state from both its learned experience and the current situation and switch its own action plan.
From our experiments we confirmed that the robot was able to achieve collaborative object manipulation when the goal state was initially shared between the human and the robot or when the inferred goal state from the initial image of a task space matched with that inferred by the human (Fig. 2). We also confirmed that successful collaboration was achieved even when the human partner changed the goal state shared before the start of the task while performing the task (Fig. 3). We speculate this is due to prediction error minimization triggered in the computational framework. The robot generated future visual predictions based on a latent goal state and current visual observations. However, when the human changed the shared goal state, a discrepancy between the predicted and actual visual states occurred. To minimize this discrepancy (or prediction errors), the latent goal state was dynamically optimized in real-time. This dynamic optimization process of the latent goal state enabled the robot to infer the intentions of the human partner and to respond to situations that were different from those assumed. By visualizing the latent goal space of the framework, we confirmed a transition of the latent goal state from the shared one to the one changed by the human in the middle of the task execution.

Fig. 2.
Robot-performed actions using the computational framework developed in the study.
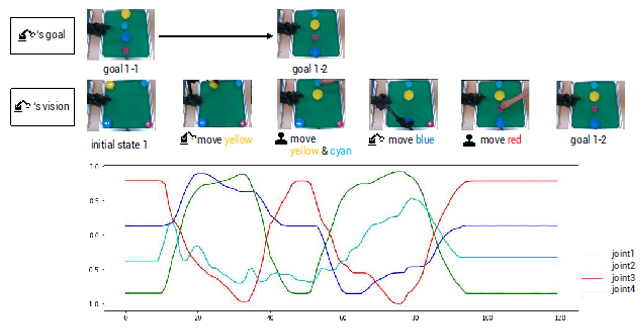
Fig. 3.
Time-development of a collaborative object arrangement task between a human and a robot (top) and time-series data of joint angles predicted by the action generation network (bottom).
In summary, we developed a deep-learning based computational framework for human-robot collaboration. The proposed framework consisted of the goal-inference network, goal-recognition network, and action-generation network. This framework enabled the robot to infer the latent goal state from only an initial image by minimizing the difference between the latent goal generated from the initial and goal images and that inferred from the initial image. We also introduced a mechanism for optimizing the inferred goal state through prediction error minimization. Experimental results demonstrated the robot's ability to infer a latent goal state from only an initial image and to generate an action while optimizing the inferred latent goal state through prediction error minimization.
Keio University Program for the Promotion of Next Generation Research Projects
The Keio University Program for the Promotion of Next Generation Research Projects subsidizes research costs with the aim of finding solutions to challenges and of promoting global academic research in order to allow Keio University faculty members to establish a presence as core researchers.