New approach for analyzing massive amounts of astronomical imaging data hints at a more efficient way to handle big data
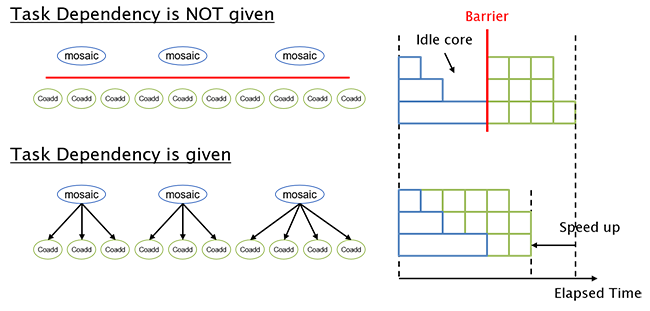
Task overlap with dependency information © Hideyuki Kawashima, Keio University
The proliferation of social media and the Internet of Things is making it increasingly difficult to process the vast amount of data that is generated every day. Thus, researchers in academia and industry are searching for methods to process data faster and more efficiently at a time when computers have stopped getting faster due to a slowdown in the famed Moore's law.
Now, Masahiro Tanaka and Hideyuki Kawashima from Keio University and Osamu Tatebe from the University of Tsukuba, describe a new method for processing data from the Subaru telescope located in Mauna Kea island, Hawaii, which could have implications for processing vast amounts of data generated every day in applications outside of astronomy.
The researchers focused on Hyper Suprime-Cam (HSC), a large camera with 116 image sensors attached to the Subaru telescope. The imaging system produces about 300 GB of raw data every night, which inflates by about ten times after processing. The data is analyzed using supercomputers with several hundred processors, called worker nodes. Rapid processing requires efficient usage of all the worker nodes for both storage and analysis.
The existing processing workflow for HSC uses the General Parallel File System (GPFS) to manage the large files that are produced. In this report, Tanaka, Kawashima, and Tatebe used a distributed file storage system called Gfarm and a parallel computing workflow called Pwrake. The Gfarm file system is designed to use distributed storage more efficiently than GPFS, while the Pwrake workflow is designed to maximize the utilization of processing cores by reducing the idle time for the processors.
The researchers found that these two improvements more than doubled the performance of the data processing pipeline compared with the existing workflow, which uses the GPFS file system. Moreover, the researchers discovered that the new workflow scales, which basically means it gets better, as more worker nodes are available for processing. Notably, this research verified scaling from 48 worker nodes up to 576 nodes.
The researchers emphasize that their results are not limited to processing astronomical data, but are applicable to other intensive data processing workflows. Hence, they could offer new clues to managing large data in other scientific and industrial applications.
Published online 29 August 2019
About the researcher

Hideyuki Kawashima ― Associate Professor
Faculty of Environment and Information StudiesHideyuki Kawashima received a Ph.D. from the Graduate School of Science and Technology, Keio University. He was a research associate at the Faculty of Science and Technology at Keio University from 2005 to 2007, and from 2007 to 2018, he was an assistant/associate professor at the Center for Computational Sciences, University of Tsukuba. In 2018, he returned to Keio University to take up a position as an associate professor at the Faculty of Environment and Information Studies.
Links
Reference
- Masahiro Tanaka; Osamu Tatebe; Hideyuki Kawashima, Applying Pwrake Workflow System and Gfarm File System to Telescope Data Processing, 2018 IEEE International Conference on Cluster Computing (CLUSTER), 10-13 Sept. 2018 | article